Чтобы обойти эту проблему, разработчики иногда отдают предпочтение мультиплексной шине. В этой шине нет разделения на адресные и информационные линии. В ней может быть, например, 32 линии и для адресов, и для данных. Сначала эти линии используются для адресов, затем — для данных. Чтобы записать информацию в память, нужно сначала передавать в память адрес, а потом — данные. В случае с отдельными линиями адреса и данные могут передаваться вместе. Объединение линий сокращает ширину и стоимость шины, но система работает при этом медленнее. Поэтому разработчикам приходится взвешивать все за и против, прежде чем сделать выбор.
Синхронизация шины
Шины можно разделить на две категории в зависимости от их синхронизации. Синхронная шина содержит линию, которая запускается кварцевым генератором. Сигнал на этой линии представляет собой меандр с частотой обычно от 5 до 100 МГц. Любое действие шины занимает целое число так называемых циклов шины. Асинхронная шина не содержит задающего генератора. Циклы шины могут быть произвольными и не обязательно одинаковыми для всех пар устройств. Далее мы рассмотрим каждый тип шины отдельно.
Синхронные шины
В качестве примера того, как работает асинхронная шина, рассмотрим временную диаграмму на рис. 3.35. В этом примере мы будем использовать задающий генератор на 100 МГц, который дает цикл шины в 10 не. Хотя может показаться, что шина работает медленно по сравнению с процессорами на 3 ГГц и выше, не многие современные шины работают быстрее. Например, популярная шина PCI работает с частотой 33 МГц или 66 МГц. О причинах такой низкой скорости современных шин уже рассказывалось: к ним можно отнести такие технические проблемы, как перекос шины и необходимость совместимости.
В нашем примере мы предполагаем, что считывание информации из памяти занимает 15 не с момента установки адреса. Как мы скоро увидим, понадобится три цикла шины, чтобы считать одно слово. Первый цикл начинается на фронте отрезка Ть а третий заканчивается на фронте отрезка Т4, как показано на рис. 3.35. Отметим, что ни один из фронтов и спадов не нарисован вертикальным, потому что ни один электрический сигнал не может изменять свое значение за нулевое время. В нашем примере мы предполагаем, что для изменения сигнала требуется 1 не. Генератор и линии адреса и данных, а также линии MREQ, RD, WAIT показаны в том же масштабе времени.
Начало Tt определяется фронтом генератора. За время Tt центральный процессор помещает адрес нужного слово на адресные линии. Поскольку адрес представляет собой не одно значение (в отличие от генератора), мы не можем
показать его в виде одной линии на схеме. Вместо этого мы показали его в виде двух линий с пересечениями там, где этот адрес меняется. Серый цвет на схеме показывает, что в этот момент не важно, какое значение принял сигнал. Используя то же соглашение, мы видим, что содержание линий данных не имеет значения до отрезка Т3.
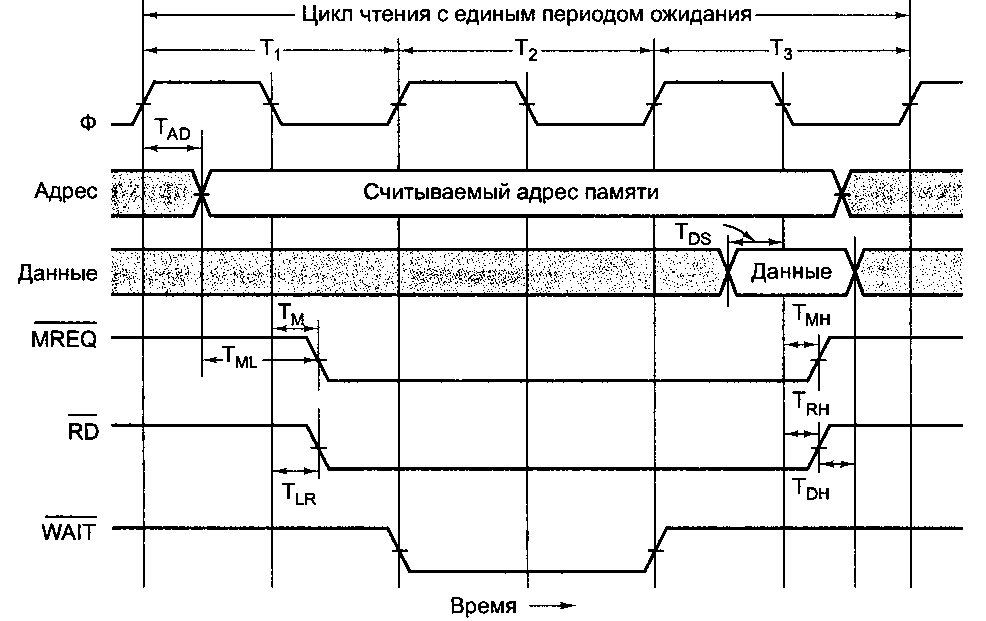
Рис. 3.35. Временная диаграмма процесса считывания на синхронной шине
После того как у адресных линий появляется возможность приобрести новое значение, устанавливаются сигналы MREQ и RD. Первый указывает, что осуществляется доступ к памяти, а не к устройству ввода-вывода, а второй — что осуществляется чтение, а не запись. Поскольку после установки адреса считывание информации из памяти занимает 15 не (часть первого цикла), память не может передать требуемые данные за период Т2. Чтобы центральный процессор не ожидал поступления данных, память устанавливает сигнал WAIT в начале отрезка Т2. Это означает ввод периодов ожидания (дополнительных циклов шины) до тех пор, пока память не сбросит сигнал WAIT. В нашем примере вводится один период ожидания (Т2), поскольку память работает слишком медленно. В начале отрезка Т3, когда есть уверенность в том, что память получит данные в течение текущего цикла, сигнал WAIT сбрасывается.