нашего
сайта:

| Статус нашего сайта: |
|
ICQ Information Center |
 ICQ SHOP ICQ SHOP5-значные 6-значные 7-значные 8-значные 9-значные Rippers List ОПЛАТА СТАТЬИ СЕКРЕТЫ HELP CENTER OWNED LIST РОЗЫСК!New! ICQ РЕЛИЗЫ Протоколы ICQ LOL ;-) Настройка компьютера Аватарки Смайлики СОФТMail Checkers Bruteforces ICQTeam Soft 8thWonder Soft Other Progs ICQ Patches Miranda ICQ ФорумАрхив! ВАШ АККАУНТ
РекламаНаш канал:irc.icqinfo.ru |
Таненбаум Э.- Архитектура компьютера. стр.494Планирование Программистам систем MPI несложно разрабатывать задания, в которых запросы делаются сразу к нескольким процессорам и которые выполняются достаточно долго. При наличии нескольких запросов от нескольких пользователей для обработки каждого запроса задействуется разное количество процессоров на разное время. Поэтому кластеру необходим планировщик, определяющий, когда запускать каждое из заданий. В простейшей модели планировщику заданий достаточно знать, сколько процессоров требуется для выполнения каждого задания. В этой модели задания выстраиваются строго в порядке FIFO (рис. 8.38, а). Когда первое задание начинает выполняться, планировщик проверяет, достаточно ли процессоров для выполнения следующего по порядку задания. Если да, то оно тоже начинает выполняться, и т. д. Если нет, то система ждет, пока не освободится достаточное количество процессоров. В нашем примере кластер содержит 8 процессоров, но он вполне мог бы содержать 128 в блоках по 16 штук (получилось бы 8 групп процессоров), или в какой-нибудь другой комбинации. 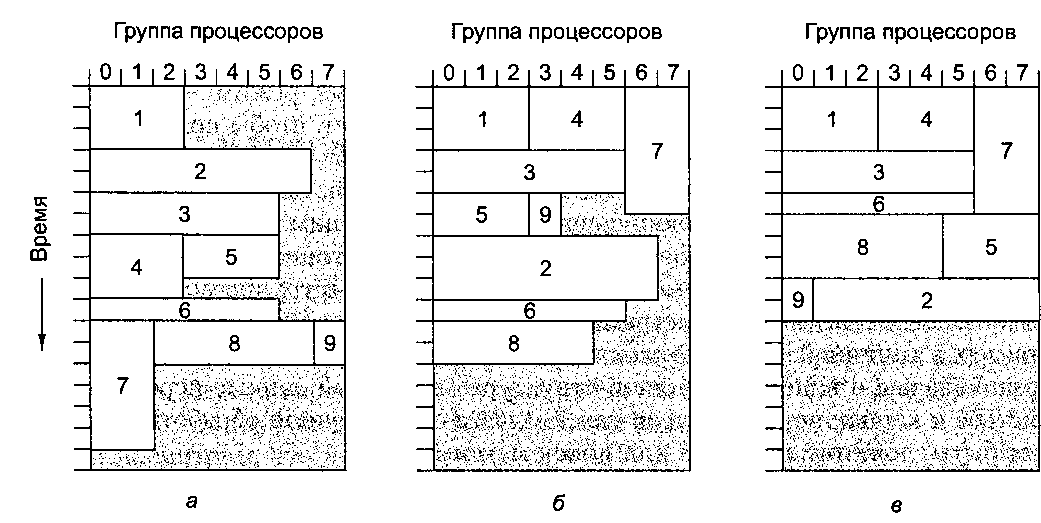 Рис. 8.38. Выполнение заданий в кластере (серым цветом показаны простаивающие процессоры): в порядке FIFO (а); без блокирования начала очереди (б); путем заполнения прямоугольника в системе координат процессоры — время (в) В более сложном алгоритме планирования удается избежать блокирования начала очереди. В этом случае все задания, для которых не хватает процессоров, пропускаются, а на выполнение ставится первое же задание, процессоров для которого достаточно. Всякий раз, когда завершается выполнение задания, очередь из оставшихся заданий проверяется в порядке FIFO (рис. 8.38, б). Еще более сложный алгоритм требует, чтобы заранее было известно, сколько процессоров нужно для выполнения каждого задания и сколько времени на это потребуется. Располагая этой информацией, планировщик заданий может попытаться заполнить заданиями прямоугольник в системе координат процессоры — время (рис. 8.38, в). Это особенно эффективно, когда задания получены днем, а выполняться должны ночью. В этом случае планировщик заданий получает всю необходимую информацию заранее, и может выполнять задания в оптимальном порядке. Общая память на прикладном уровне Из наших примеров видно, что мультикомпьютеры поддаются масштабированию гораздо лучше, чем мультипроцессоры. Этот факт привел к возникновению систем передачи сообщений, таких как MPI. Многим программистам эта модель не нравится, и они предпочли бы иметь иллюзию общей памяти, даже если ее на самом деле не существует. Если бы удалось достичь этой цели, это было бы прекрасно во всех отношениях: и в отношении удешевления аппаратуры (по крайней мере, на уровне каждого узла), и в отношении удобства программирования. Можно сказать, что это был бы Священный Грааль параллельных вычислений. Многие исследователи пришли к выводу, что общую память не обязательно строить на архитектурном уровне — существуют другие пути. Из рис. 8.17 видно, что есть несколько уровней, на которых можно организовать общую память. Далее мы узнаем, как ввести общую память в программную модель мультикомпью-тера, если аппаратно она не поддерживается. |